Сравнение надежности кластера и сервера или зачем нужны СХД
Что такое готовность?
Готовность отражает способность системы непрерывно выполнять свои функции.
Коэффициент готовности – это вероятность того, что компьютерная система в любой момент времени будет находиться в рабочем состоянии.
Этот коэффициент определяется по формуле:
K = MTBF/MTBF + MTTR
MTBF (Mean Time Between Failure) — среднее время наработки на отказ.
MTTR (Mean Time To Repair) — среднее время восстановления работоспособности.
В отличие от надежности, величина которой определяется только значением MTBF, готовность зависит еще и от времени, необходимого для возврата системы в рабочее состояние.
Что такое кластер высокой готовности?
Кластер высокой готовности (далее кластер) — это разновидность кластерной системы, предназначенная для обеспечения непрерывной работы критически важных приложений или служб. Применение кластера высокой готовности позволяет предотвратить как неплановые простои, вызываемые отказами аппаратуры и программного обеспечения, так и плановые простои, необходимые для обновления программного обеспечения или профилактического ремонта оборудования.
Принципиальная схема кластера высокой готовности приведена на рисунке:
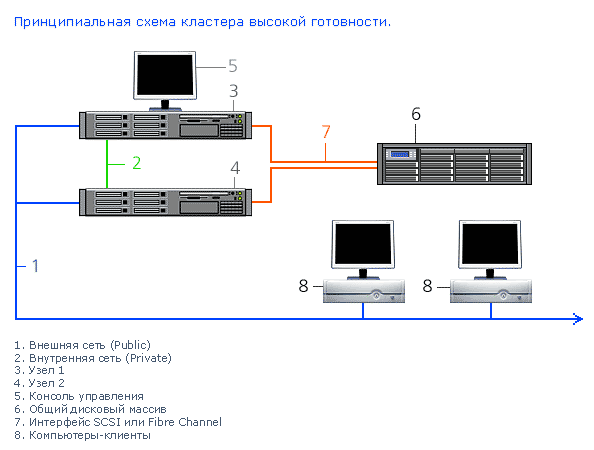
Кластер состоит из двух узлов (серверов), подключенных к общему дисковому массиву. Все основные компоненты этого дискового массива — блок питания, дисковые накопители, контроллер ввода/вывода — имеют резервирование с возможностью горячей замены. Узлы кластера соединены между собой внутренней сетью для обмена информацией о своем текущем состоянии. Электропитание кластера осуществляется от двух независимых источников. Подключение каждого узла к внешней локальной сети также дублируется.
Таким образом, все подсистемы кластера имеют резервирование, поэтому при отказе любого элемента кластер в целом останется в работоспособном состоянии. Более того, замена отказавшего элемента возможна без остановки кластера.
На обоих узлах кластера устанавливается операционная система Microsoft Windows Server 2003 Enterprise, которая поддерживает технологию Microsoft Windows Cluster Service (MSCS).
Принцип работы кластера следующий. Приложение (служба), доступность которого обеспечивается кластером, устанавливается на обоих узлах. Для этого приложения (службы) создается группа ресурсов, включающая IP-адрес и сетевое имя виртуального сервера, а также один или несколько логических дисков на общем дисковом массиве. Таким образом, приложение вместе со своей группой ресурсов не привязывается «жестко» к конретному узлу, а, напротив, может быть запущено на любом из этих узлов (причем на каждом узле одновременно может работать несколько приложений). В свою очередь, клиенты этого приложения (службы) будут «видеть» в сети не узлы кластера, а виртуальный сервер (сетевое имя и IP-адрес), на котором работает данное приложение.
Сначала приложение запускается на одном из узлов. Если этот узел по какой-либо причине прекращает функционировать, другой узел перестает получать от него сигнал активности («heartbeat») и автоматически запускает все приложения отказавшего узла, т.е. приложения вместе со своими группами ресурсов «мигрируют» на исправный узел. Миграция приложения может продолжаться от нескольких секунд до нескольких десятков секунд и в течение этого времени данное приложение недоступно для клиентов. В зависимости от типа приложения после рестарта сеанс возобновляется автоматически либо может потребоваться повторная авторизация клиента. Никаких изменений настроек со стороны клиента не нужно. После восстановления неисправного узла его приложения могут мигрировать обратно.
Если на каждом узле кластера работают различные приложения, то в случае отказа одного из узлов нагрузка на другой узел повысится и производительность приложений упадет.
Если приложения работают только на одном узле, а другой узел используется в качестве резерва, то при отказе «рабочего» узла производительность кластера не изменится (при условии, что запасной узел не «слабее»).
Основным преимуществом кластеров высокой готовности является возможность использования стандартного оборудования и программного обеспечения, что делает это решение недорогим и доступным для внедрения предприятиями малого и среднего бизнеса.
Следует отличать кластеры высокой готовности от отказоустойчивых систем («fault-tolerant»), которые строятся по принципу полного дублирования. В таких системах серверы работают параллельно в синхронном режиме. Достоинством этих систем является малое (меньше секунды) время восстановления после отказа, а недостатком — высокая стоимость из-за необходимости применения специальных программных и аппаратных решений.
Сравнение кластера высокой готовности с обычным сервером
Как упоминалось выше, применение кластеров высокой готовности позволяет уменьшить число простоев, вызванное плановыми или неплановыми остановками работы.
Плановые остановки могут быть обусловлены необходимостью обновления программного обеспечения или проведения профилактического ремонта оборудования. На кластере эти операции можно проводить последовательно на разных узлах, не прерывая работы кластера в целом.
Неплановые остановки случаются из-за сбоев программного обеспечения или аппаратуры. В случае сбоя ПО на обычном сервере потребуется перезагрузка операционной системы или приложения, в случае с кластером приложение мигрирует на другой узел и продолжит работу.
Наименее предсказуемым событием является отказ оборудования. Из опыта известно, что сервер является достаточно надежным устройством. Но можно ли получить конкретные цифры, отражающие уровень готовности сервера и кластера?
Производители компьютерных компонентов, как правило, определяют их надежность на основании испытаний партии изделий по следующей формуле:
MTBF = Время теста х Число тестируемых изделий/Число изделий, вышедшее из строя
Например, если тестировалось 100 изделий в течение года и 10 из них вышло из строя, то MTBF, вычисленное по этой формуле, будет равно 10 годам. Т.е. предполагается, что через 10 лет все изделия выйдут из строя.
Отсюда можно сделать следующие важные выводы. Во-первых, такая методика расчета MTBF предполагает, что число отказов в единицу времени постоянно на протяжении всего срока эксплуатации. В «реальной» жизни это, конечно, не так. На самом деле, из теории надежности известно, что кривая отказов имеет следующий вид:
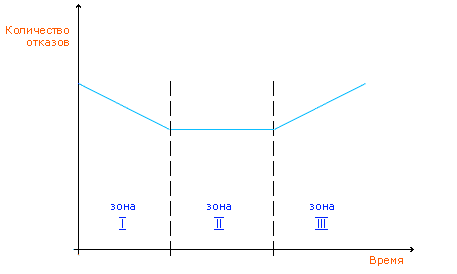
В зоне I проявляются отказы изделий, имеющие дефекты изготовления. В III зоне начинают сказываться усталостные изменения. В зоне II отказы вызываются случайными факторами и их число постоянно в единицу времени. Изготовители компонентов, «распространяют» эту зону на весь срок эксплуатации. Реальная статистика отказов на протяжение всего срока эксплуатации подтверждает, что эта теоретическая модель вполне близка к действительности.
Второй интересный вывод заключается в том, что понятие MTBF отражает совсем не то, что очевидно следует из его названия. «Среднее время наработки на отказ» в буквальном смысле означает время, составляющее только половину MTBF. Так, в нашем примере это «среднее время» будет не 10 лет, а пять, поскольку в среднем все экземпляры изделия проработают не 10 лет, а вполовину меньше. Т.е. MTBF, заявляемый производителем — это время, в течение которого изделие выйдет из строя с вероятностью 100%.
Итак, поскольку вероятность выхода компонента из строя на протяжении MTBF равна 1, и если MTBF измерять в годах, то вероятность выхода компонента из строя в течение одного года составит:
P =1/MTBF
Очевидно, что отказ любого из недублированных компонентов сервера будет означать отказ сервера в целом.
Отказ дублированного компонента приведет к отказу сервера только при условии, что компонент-дублер тоже выйдет из строя в течение времени, необходимого для «горячей» замены компонента, отказавшего первым. Если гарантированное время замены компонента составляет 24 часа (1/365 года) (что соответствует сложившейся практике обслуживания серверного оборудования), то вероятность такого события в течение года:
Md =P x P/365 x 2
Теперь, зная вероятность отказа всех N компонентов (дублированных и недублированных) сервера, можно рассчитать вероятность отказа сервера в течение одного года:
Ps = ∑Pi
Поскольку отказы сервера (отказы компонент) распределены во времени равномерно, то, зная вероятность отказа сервера в течение года, можно определить время его наработки на отказ (время, через которое сервер выйдет из строя с вероятностью 100%):
MTBFs =1/Ps
Теперь можно определить коэффициент готовности:
Ks =MTBFs/MTBFs + MTTRs
Перейдем к расчету. Пусть наш сервер состоит из следующих компонентов:
Сведем данные производителей по надежности отдельных компонент, а также данные по реальной статистике отказов, предоставленные нашим сервисным центром, в следующую таблицу:
| Компоненты сервера | Заявленная надежность | Вер-ть отказа за год(факт.) |
Вер-ть отказа за год(сред.) |
Кол-во эл-тов в серв. |
Вер-ть отказа с учетом дублир-я |
||
| MTBF (часов) |
MTBF (лет) |
Вер-ть от- каза за год |
|||||
| Блок питания | 90 000 | 10 | 0,097 | 0,043 | 0,070 | 2 | 0,00003 |
| Системная плата | 300 000 | 34 | 0,029 | 0,003 | 0,016 | 1 | 0,01606 |
| Процессор №1 | 1 000 000 | 114 | 0,009 | 0,001 | 0,005 | 1 | 0,00477 |
| Процессор №2 | 1 000 000 | 114 | 0,009 | 0,001 | 0,005 | 1 | 0,00477 |
| RAM, модуль №1 | 1 000 000 | 114 | 0,009 | 0,003 | 0,006 | 1 | 0,00613 |
| RAM, модуль №2 | 1 000 000 | 114 | 0,009 | 0,003 | 0,006 | 1 | 0,00613 |
| Жесткий диск | 400 000 | 46 | 0,022 | 0,013 | 0,018 | 2 | 0,00000 |
| Вентилятор №1 | 100 000 | 11 | 0,088 | 0,001 | 0,045 | 2 | 0,00001 |
| Вентилятор №2 | 100 000 | 11 | 0,088 | 0,001 | 0,045 | 2 | 0,00001 |
| Контроллер HDD | 300 000 | 34 | 0,029 | 0,006 | 0,018 | 1 | 0,01752 |
| Плата сопряжения | 300 000 | 34 | 0,029 | 0,012 | 0,020 | 1 | 0,02043 |
| Ленточный накопитель | 220 000 | 25 | 0,040 | 0,020 | 0,030 | 1 | 0,02991 |
| Итого: | 0,457 | 0,108 | 0,282 | 0,10576 | |||
Тогда:
Вероятность отказа сервера в течение года: 0,106
MTBF сервера (лет): 9,455
Среднее время устранения неисправности (часов): 24
Коэффициент готовности сервера (%): 99,97
Среднее время простоя в год (часов): 2.54
Вообще, для серверного оборудования нормальным коэффициентом готовности считается величина 99,95%, что примерно соответствует результату наших расчетов.
Выполним аналогичный расчет для кластера.
Кластер состоит из двух узлов и внешнего дискового массива. Нарушение работоспособности кластера произойдет либо в случае отказа дискового массива либо в случае одновременного отказа обеих узлов в течение времени, необходимого для восстановления узла, первым вышедшего из строя.
Предположим, что в качестве узла кластера используется рассмотренный нами сервер с коэффициентом готовности K = 99,97%, а время восстановления работоспособности узла — 24 часа.
Рассчитаем параметры надежности внешнего дискового массива:
| Компоненты сервера | Заявленная надежность | Вер-ть отказа за год(факт.) |
Вер-ть отказа за год(сред.) |
Кол-во эл-тов в серв. |
Вер-ть отказа с учетом дублир-я |
||
| MTBF (часов) |
MTBF (лет) |
Вер-ть от- каза за год |
|||||
| Блок питания | 90 000 | 10 | 0,097 | 0,043 | 0,070 | 2 | 0,00003 |
| Жесткий диск | 400 000 | 46 | 0,022 | 0,013 | 0,018 | 2 | 0,00000 |
| Вентилятор | 100 000 | 11 | 0,088 | 0,001 | 0,045 | 2 | 0,00001 |
| Контроллер HDD | 300 000 | 34 | 0,029 | 0,006 | 0,018 | 2 | 0,00000 |
| Итого: | 0,236 | 0,063 | 0,150 | 0,00004 | |||
Вероятность отказа массива в течение года: Pm = 0,00004
Вероятность отказа одного из узлов в течение года: Pn = 0,106
Вероятность отказа кластера в течение года: P = Pm + 2 x Pn x Pn /365 = 0,0001
Время наработки на отказ для кластера (лет): MTBF = 1 / P = 9 739
Время восстановления после отказа (часов): MTTR = 24
Коэффициент готовности кластера (%): K = 99,99997
Среднее время простоя в течение года (секунд): T = 8
Таким образом, кластер высокой готовности демонстрирует гораздо более высокую устойчивость к возможному отказу аппаратуры, нежели сервер традиционной архитектуры.
На нашем сайте вы можете приобрести системы хранения данных б/у с гарантией по отличным ценам.
© OOO “Cерверы для профессионалов” 2015—2022
Перепечатка статей со ссылкой на источник разрешается и приветствуется.